 QHexRT
QHexRTJune 25, 2026
QHexRT Is Live: Full-Stack NPU Inference for Qualcomm Hexagon
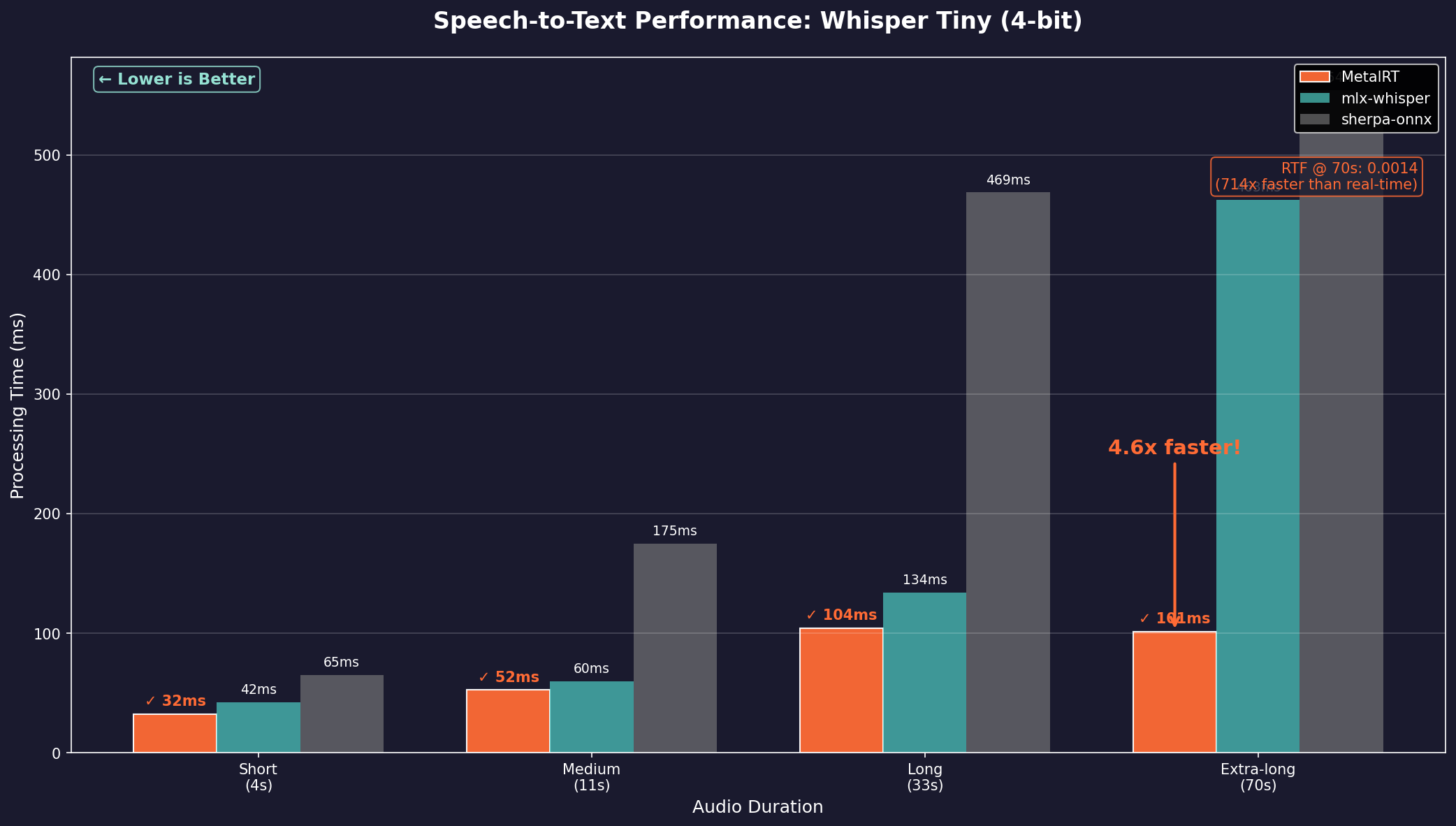
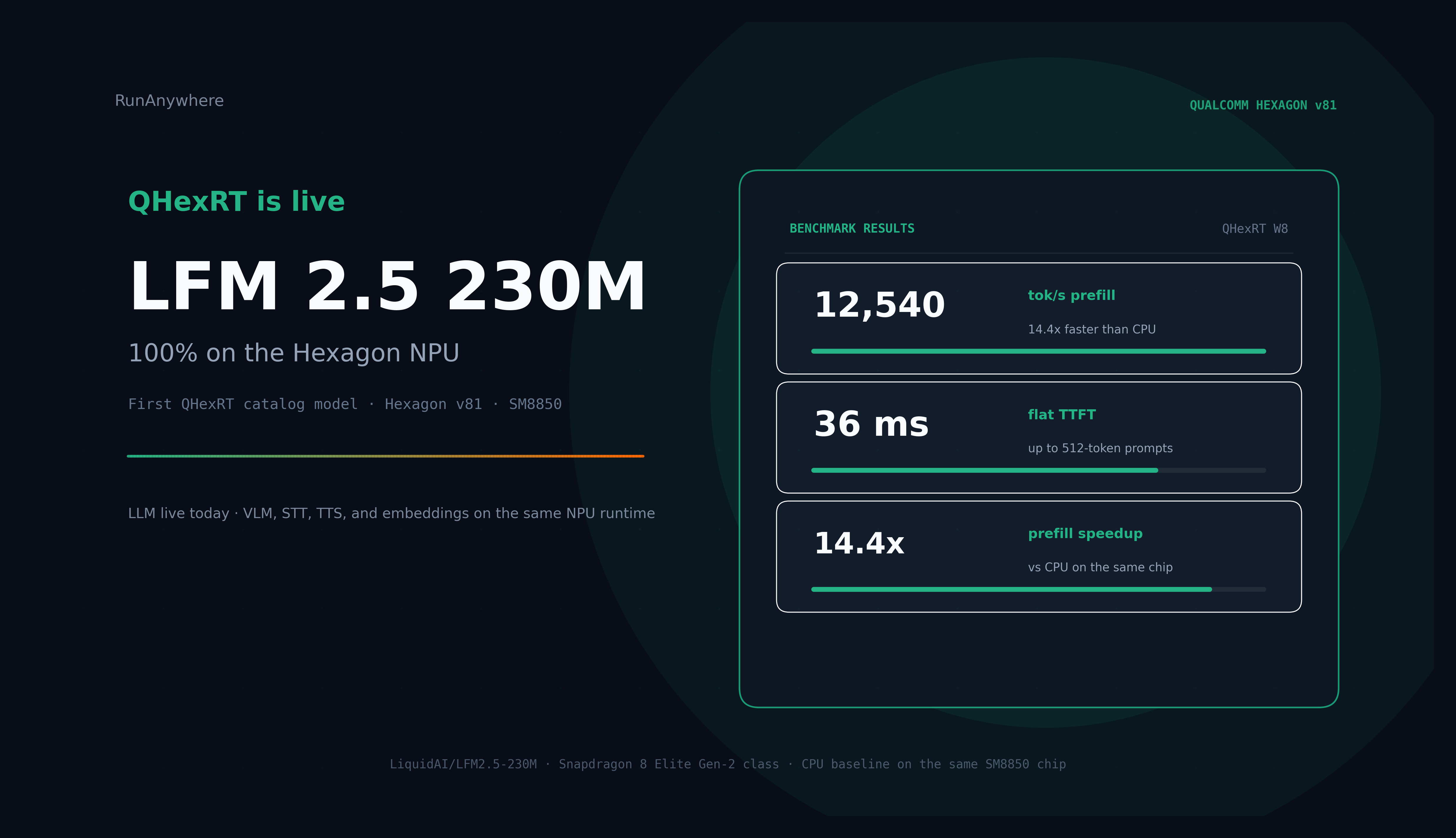
QHexRT is officially live — the first inference engine built to run LLM, VLM, STT, TTS, and embeddings 100% on Qualcomm Hexagon NPUs. First model: LFM 2.5 230M at 12,540 tok/s prefill and 36ms flat TTFT on v81.