Weekly briefing · Inference Radar
The state of open-source
inference, every week.
Automated, citation-backed briefings on the repositories that actually move the AI inference stack — vLLM, llama.cpp, MLX, TensorRT-LLM, and 130+ more. Produced by Inference Radar, our research arm for tracking the open-source inference ecosystem.
Latest issue
Read full briefing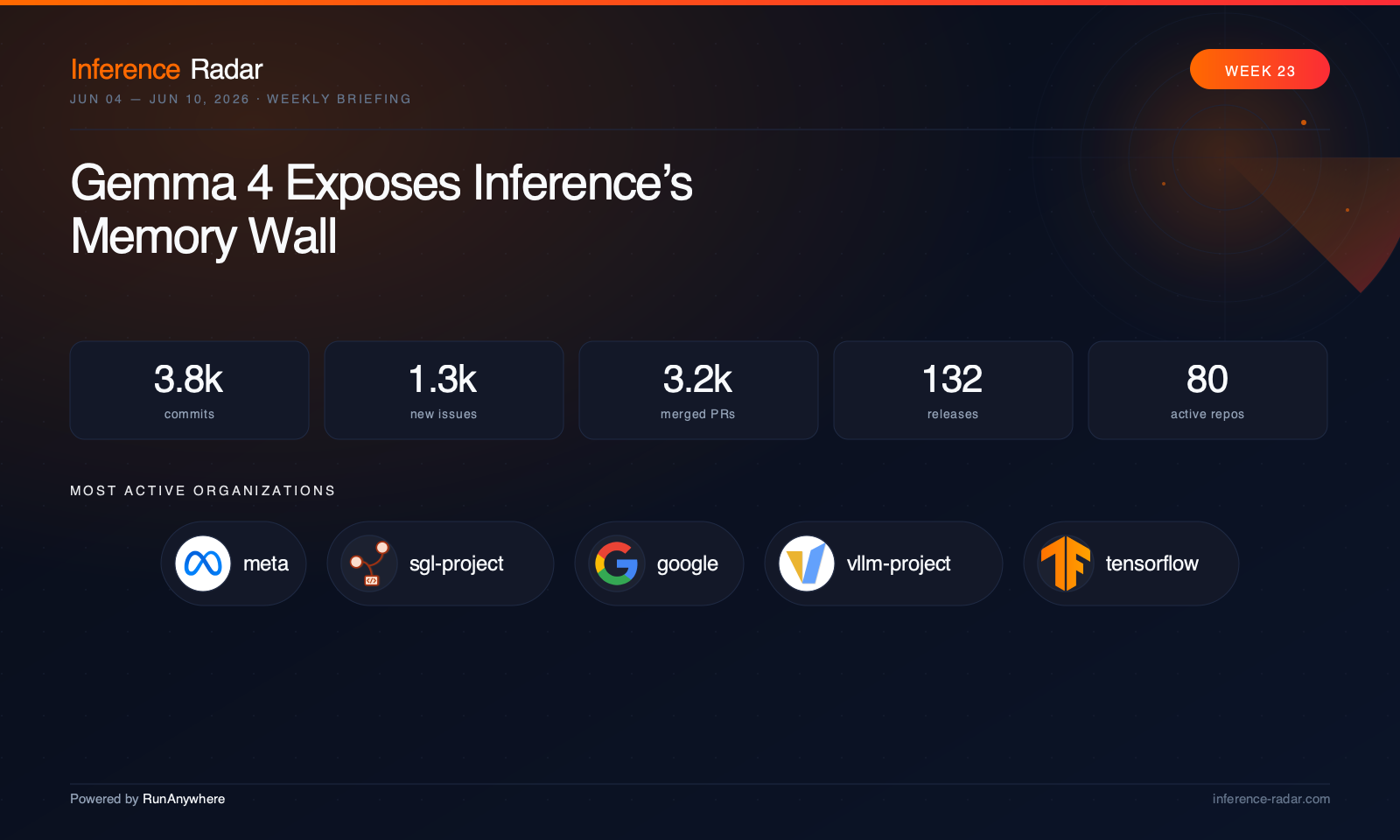
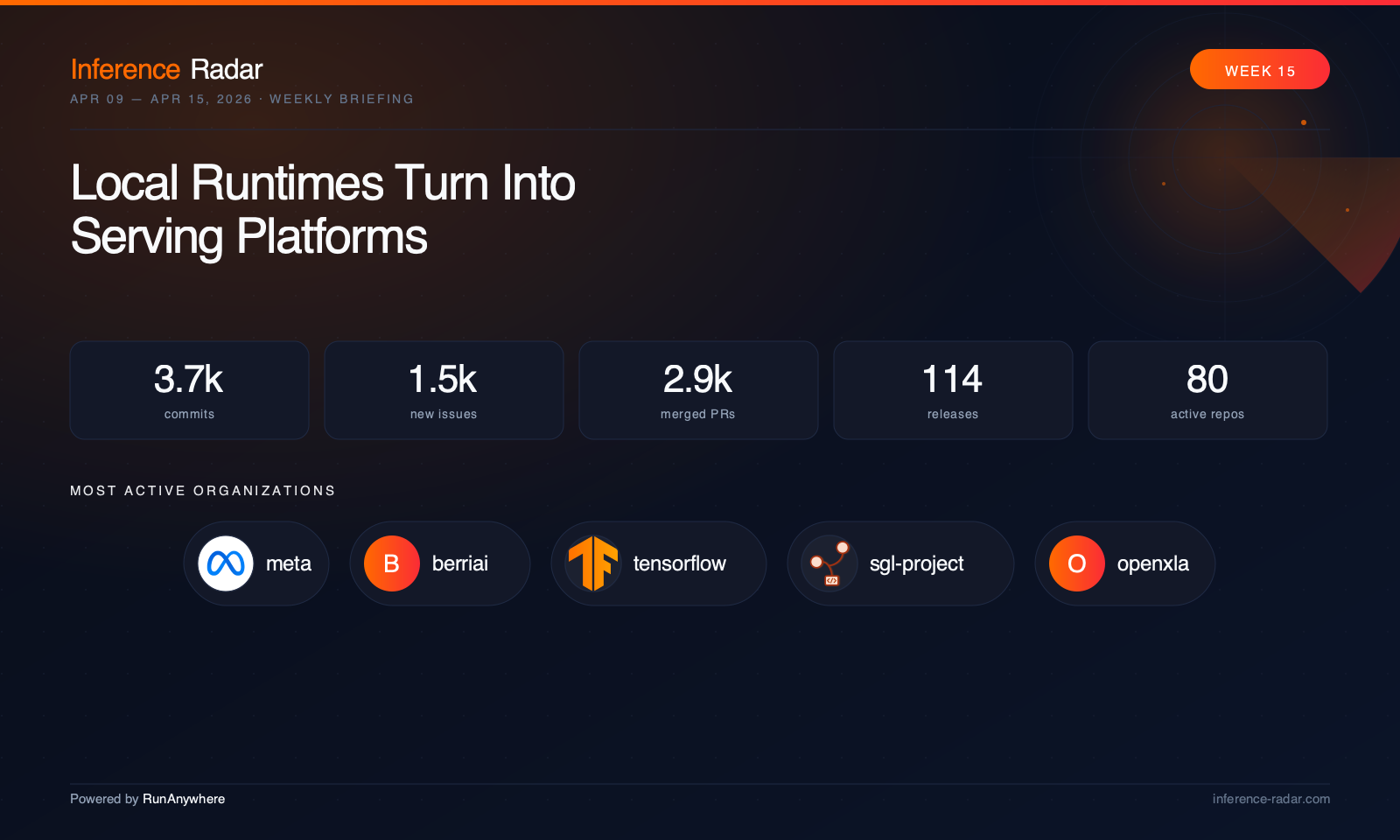
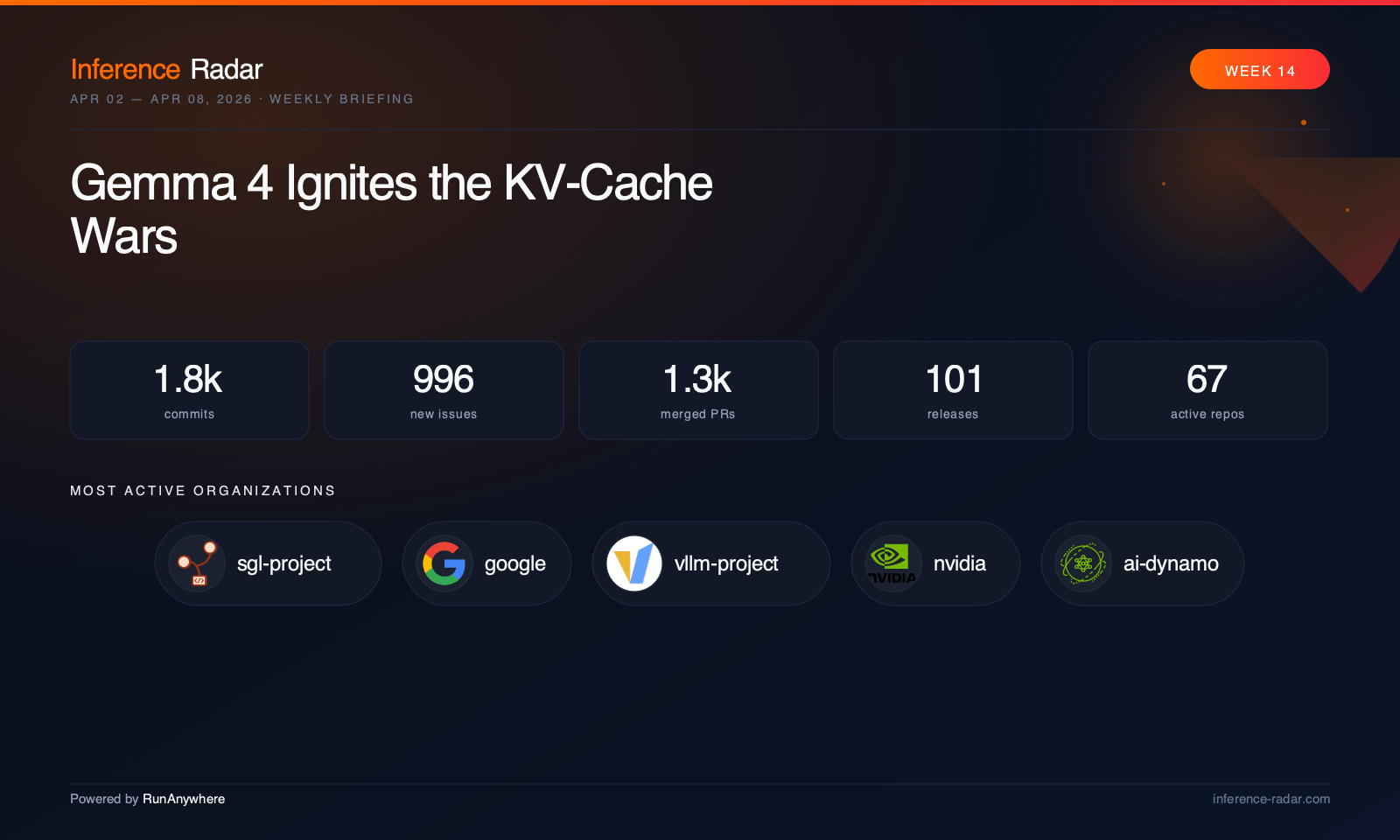
Gemma 4 Exposes Inference’s Memory Wall
“This week made the inference stack feel like one continuous memory hierarchy: cloud servers, local runtimes, browser engines, mobile frameworks, and edge NPUs are all fighting the same bottlenecks. The center of gravity moved from “can this model run?” to “can this model stream, cache, quantize, route, and recover under real workloads?””
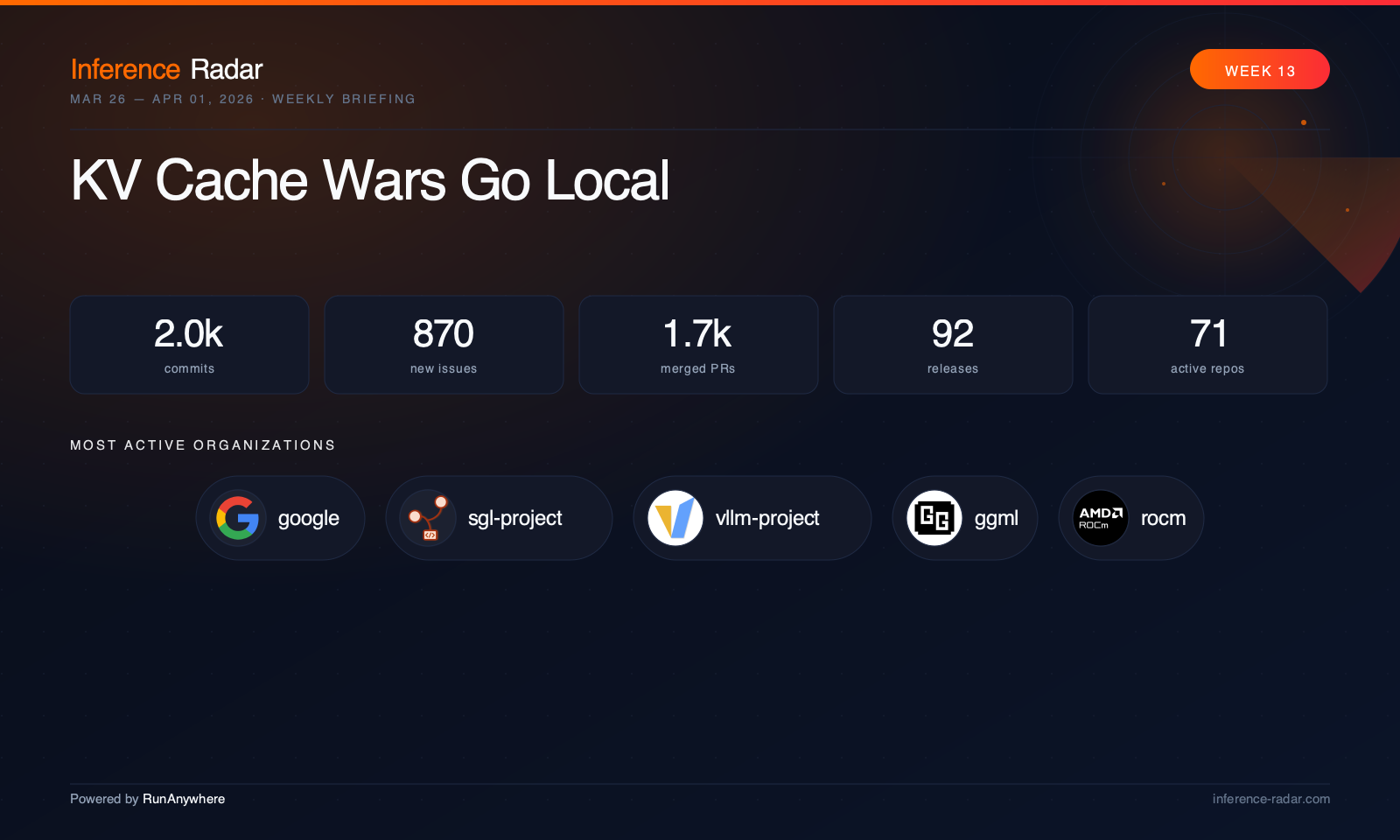
Archive
Every issue we've published.
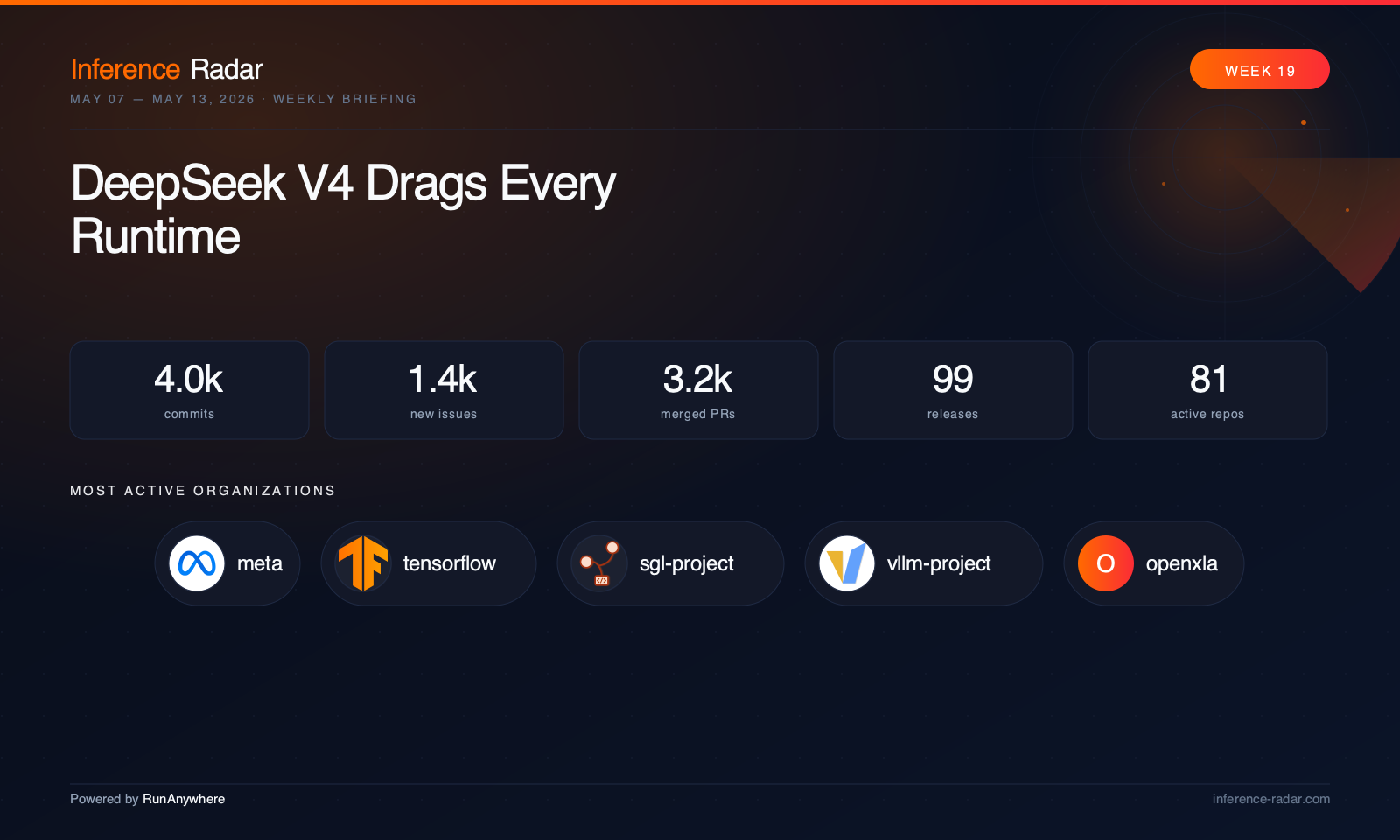
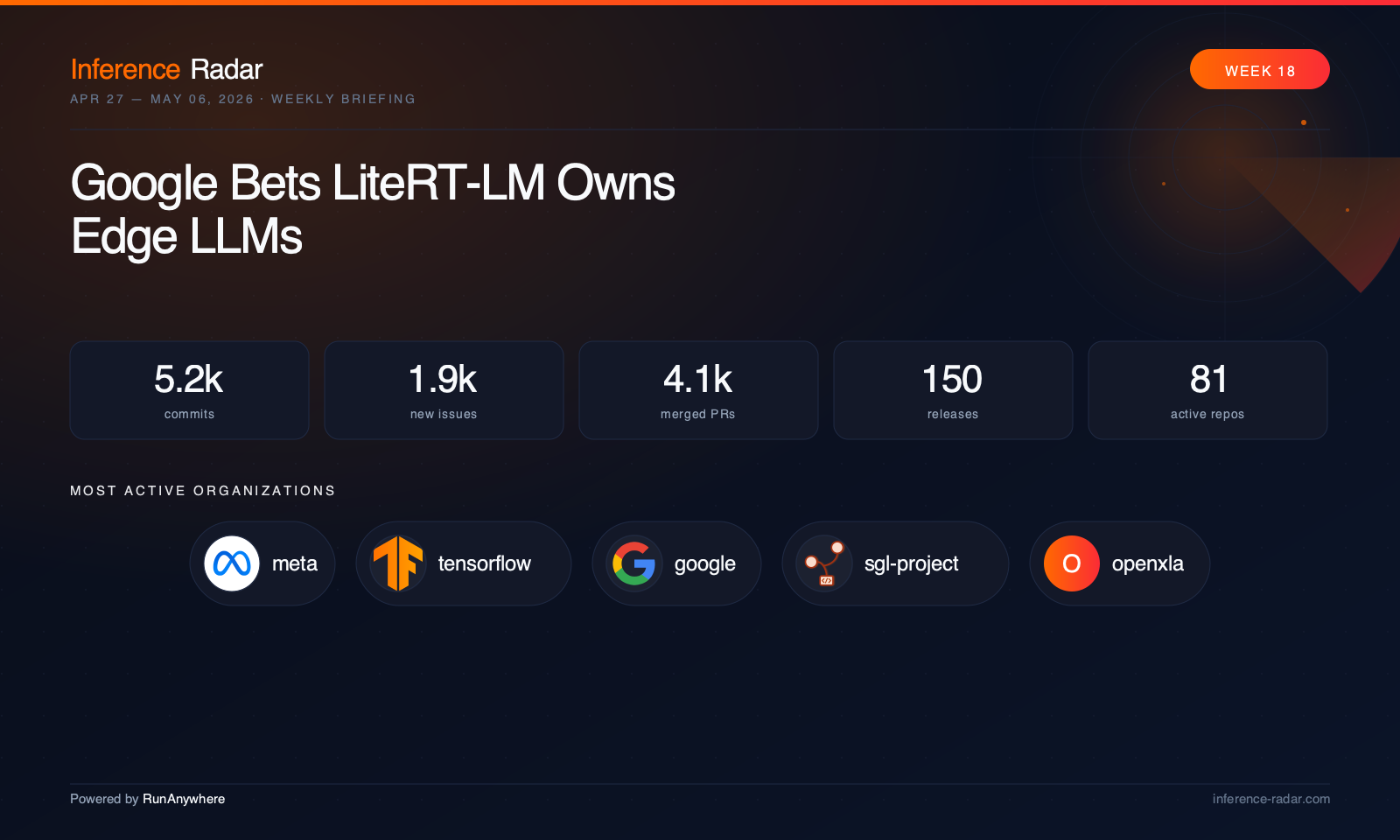
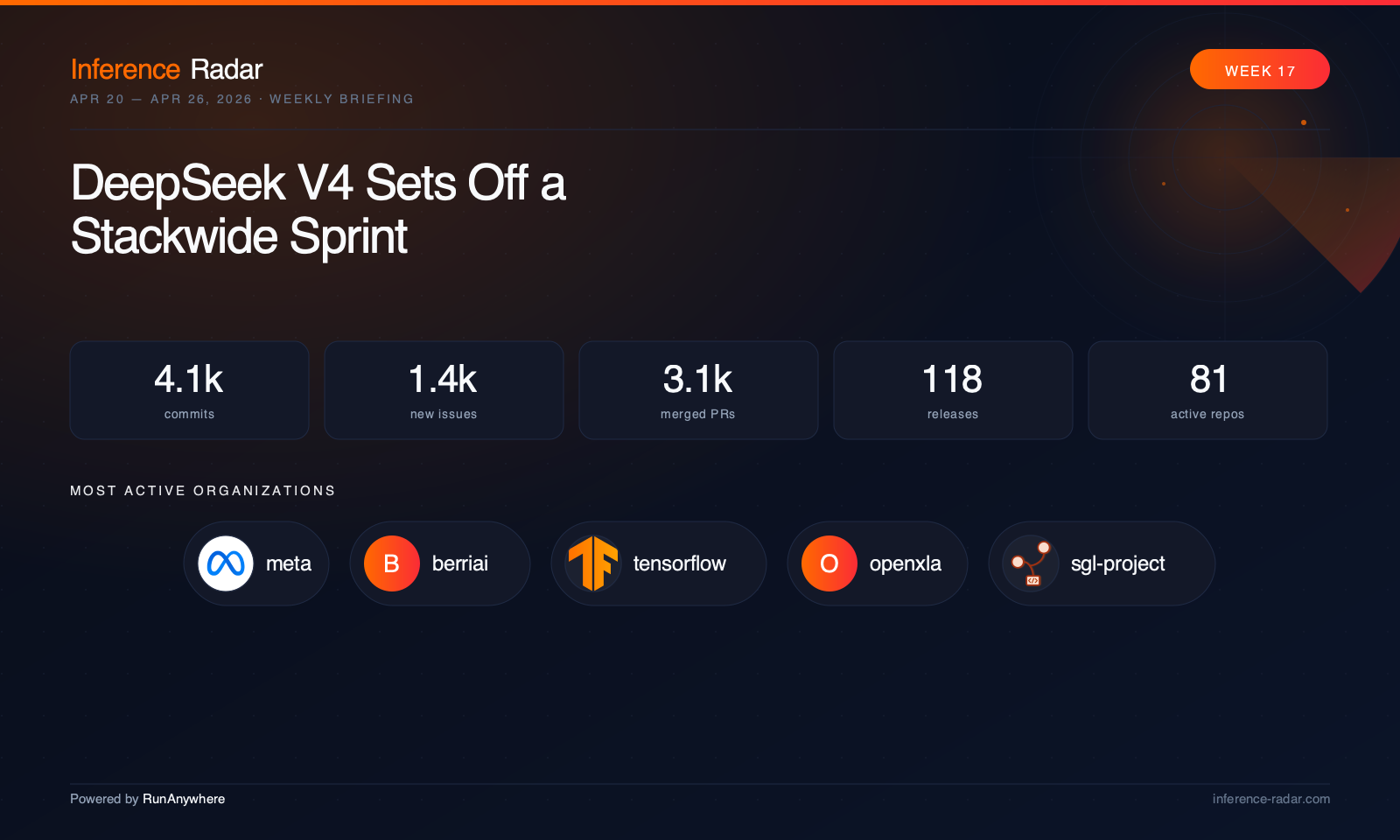
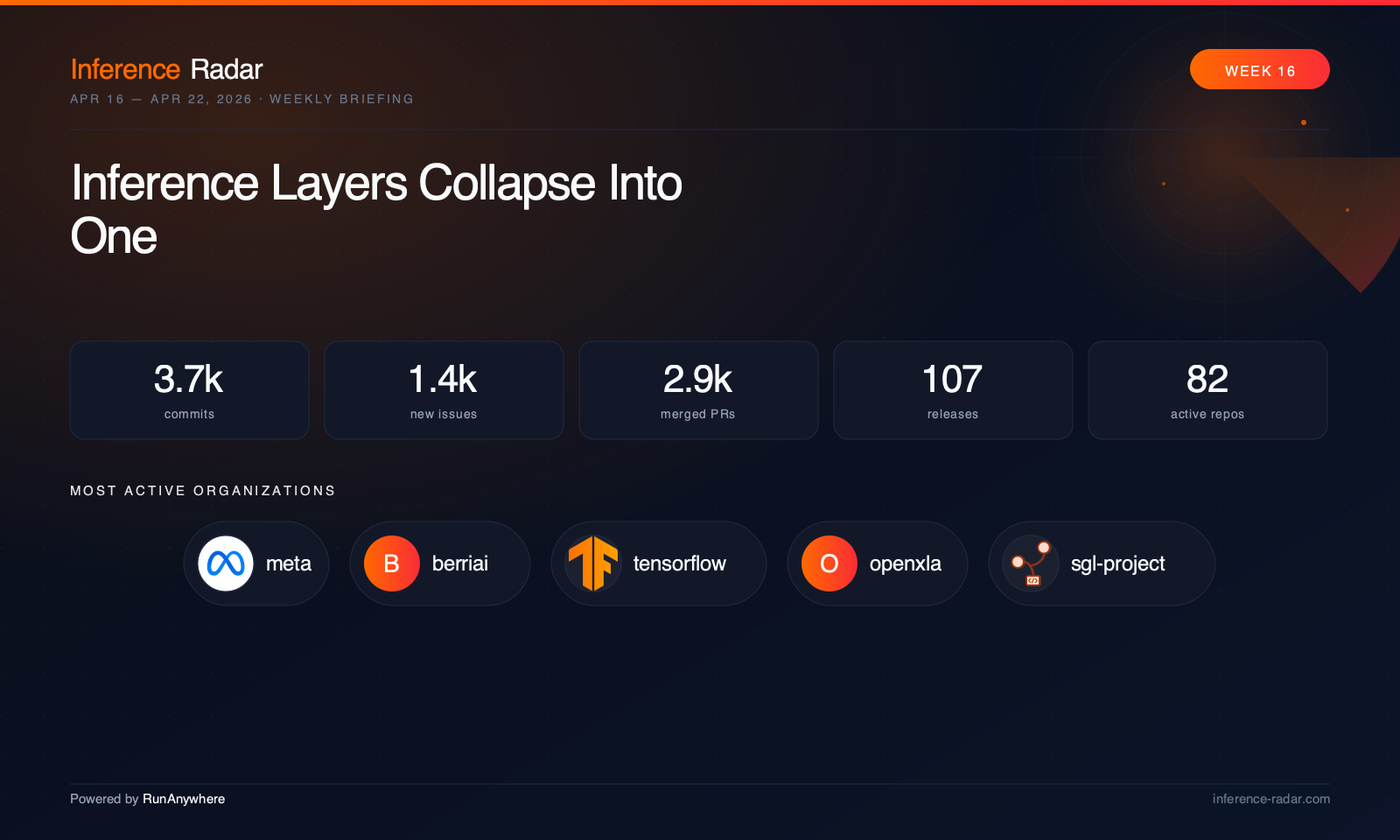
Powered by RunAnywhere
The signal,
not the noise.
A weekly briefing for engineers who ship inference infrastructure for a living. Every link is cited. Every claim is grounded in code.