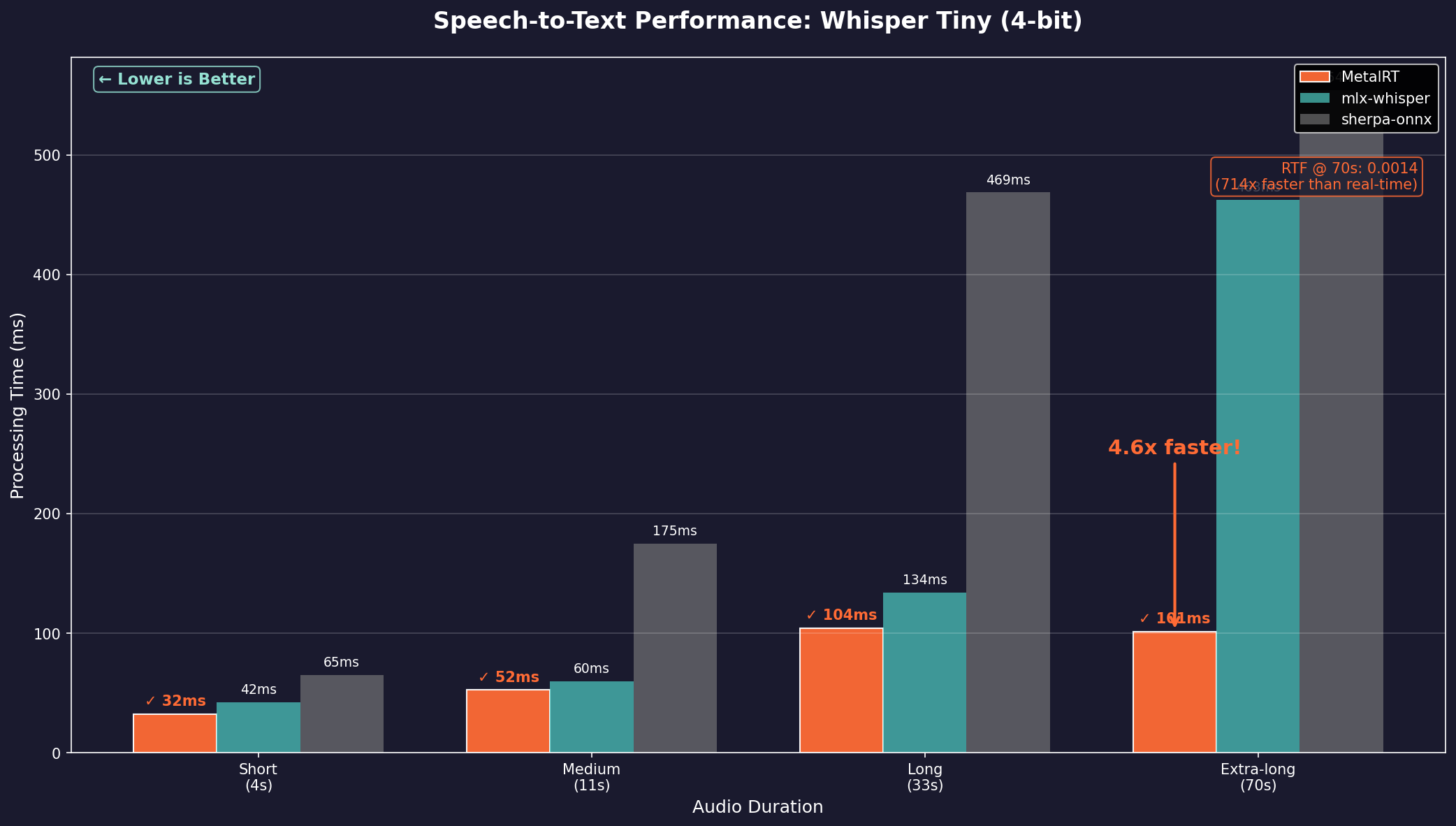
We Built the Fastest LLM Decode Engine for Apple Silicon. Here Are the Numbers.
 DEVELOPERS
DEVELOPERSHow fast can you run an LLM on Apple Silicon if you throw away every abstraction and go straight to the metal?
658 tokens per second. All on a single M4 Max.
We benchmarked MetalRT against five engines across four models. MetalRT won decode on 3 of 4 models and averaged 1.67x faster than llama.cpp.
We tested against:
- uzu - production-grade Rust inference engine
- mlx-lm - Apple's MLX inference framework
- llama.cpp - the most widely-used open-source inference engine
- Ollama - popular llama.cpp wrapper with REST API (v0.17.4)
Setup
| Engine | Language | Benchmark Method |
|---|---|---|
| MetalRT | C++ | Native binary |
| uzu | Rust | Native cli bench |
| mlx-lm | Python + MLX C++ | Python API |
| llama.cpp | C/C++ | llama-bench v8190 |
| Ollama | Go + llama.cpp | REST API (streaming) |
- Hardware: Apple M4 Max, 64 GB unified memory, macOS 26.3
- Models: Qwen3-0.6B, Qwen3-4B, Llama-3.2-3B, LFM2.5-1.2B (all 4-bit quantized)
- Runs: 5 per engine per model, best reported
- Fairness: MetalRT and mlx-lm use the exact same model files. Ollama uses the same GGUF files as llama.cpp, with REST API overhead included.
Decode Speed
Decode speed is how fast tokens stream to the user. It is the metric that matters most for interactive chat.

| Model | MetalRT | uzu | mlx-lm | llama.cpp | Ollama |
|---|---|---|---|---|---|
| Qwen3-0.6B | 658 | 627 | 552 | 295* | 274 |
| Qwen3-4B | 186 | 165 | 170 | 87 | 120 |
| Llama-3.2-3B | 184 | 222 | 210 | 137 | 131 |
| LFM2.5-1.2B | 570 | 550 | 509 | 372 | 313 |
*Qwen3-0.6B llama.cpp/Ollama use Q8_0 (8-bit), not directly comparable.
MetalRT wins 3 of 4 models. The speedups:
- 1.10-1.19x vs mlx-lm (same model files)
- 1.35-2.14x vs llama.cpp
- 1.41-2.40x vs Ollama
uzu wins Llama-3.2-3B at 222 tok/s. We report this honestly.
MetalRT vs Apple MLX and llama.cpp
mlx-lm is Apple's official inference framework. MetalRT and mlx-lm use the exact same model files, so this is a pure engine-to-engine comparison.

MetalRT is 1.10-1.19x faster than mlx-lm on decode (same model files) and 1.35-2.14x faster than llama.cpp across the board.
What MetalRT Is Built For
| Use Case | Why MetalRT |
|---|---|
| Chat apps | 186 tok/s on a 4B model, responses stream instantly |
| Structured output / tool calling | Faster decode = faster JSON and function call generation |
| Agent workflows | Compound latency savings across sequential LLM calls |
| Coding assistants | Sub-7ms TTFT on small models |
| Privacy-first apps | Cloud-competitive speed, entirely on-device |
| Voice pipelines | Faster decode shrinks the gap between hearing and responding |
Summary
- 658 tok/s peak decode (Qwen3-0.6B)
- 1.67x faster than llama.cpp on decode
- 1.19x faster than mlx-lm on decode (same model files)
- 1.59x faster than Ollama on decode
- 6.6ms time-to-first-token (Qwen3-0.6B)
Output quality is identical across all engines. The model is the same. The speed is not.
Benchmarked on Apple M4 Max, 64 GB, macOS 26.3. Models: Qwen3-0.6B, Qwen3-4B, Llama-3.2-3B, LFM2.5-1.2B, all 4-bit. Greedy decoding, 5 runs, best reported. MetalRT + mlx-lm share identical MLX 4-bit model files. llama.cpp and Ollama use GGUF Q4_K_M (Q8_0 for Qwen3-0.6B). Ollama v0.17.4 via REST API, TTFT measured end-to-end.