 MetalRT
MetalRTMarch 15, 2026
MetalRT Now Does Speech-to-Speech. 1.52x Faster Than mlx-audio.
MetalRT adds native speech-to-speech support. 1.68s end-to-end latency, 123 tok/s generation throughput, 1.52x faster than mlx-audio on a single M4 Max.
Backed by Y Combinator
Engineering notes from every layer of the on-device stack
MetalRTMarch 15, 2026
MetalRT adds native speech-to-speech support. 1.68s end-to-end latency, 123 tok/s generation throughput, 1.52x faster than mlx-audio on a single M4 Max.
 MetalRT
MetalRTMarch 13, 2026
MetalRT adds VLM support and wins every decode benchmark. 279 tok/s vision decode, 92ms time-to-output, 1.22x faster than mlx-vlm across all resolutions on a single M4 Max.
 MetalRT
MetalRTMarch 9, 2026
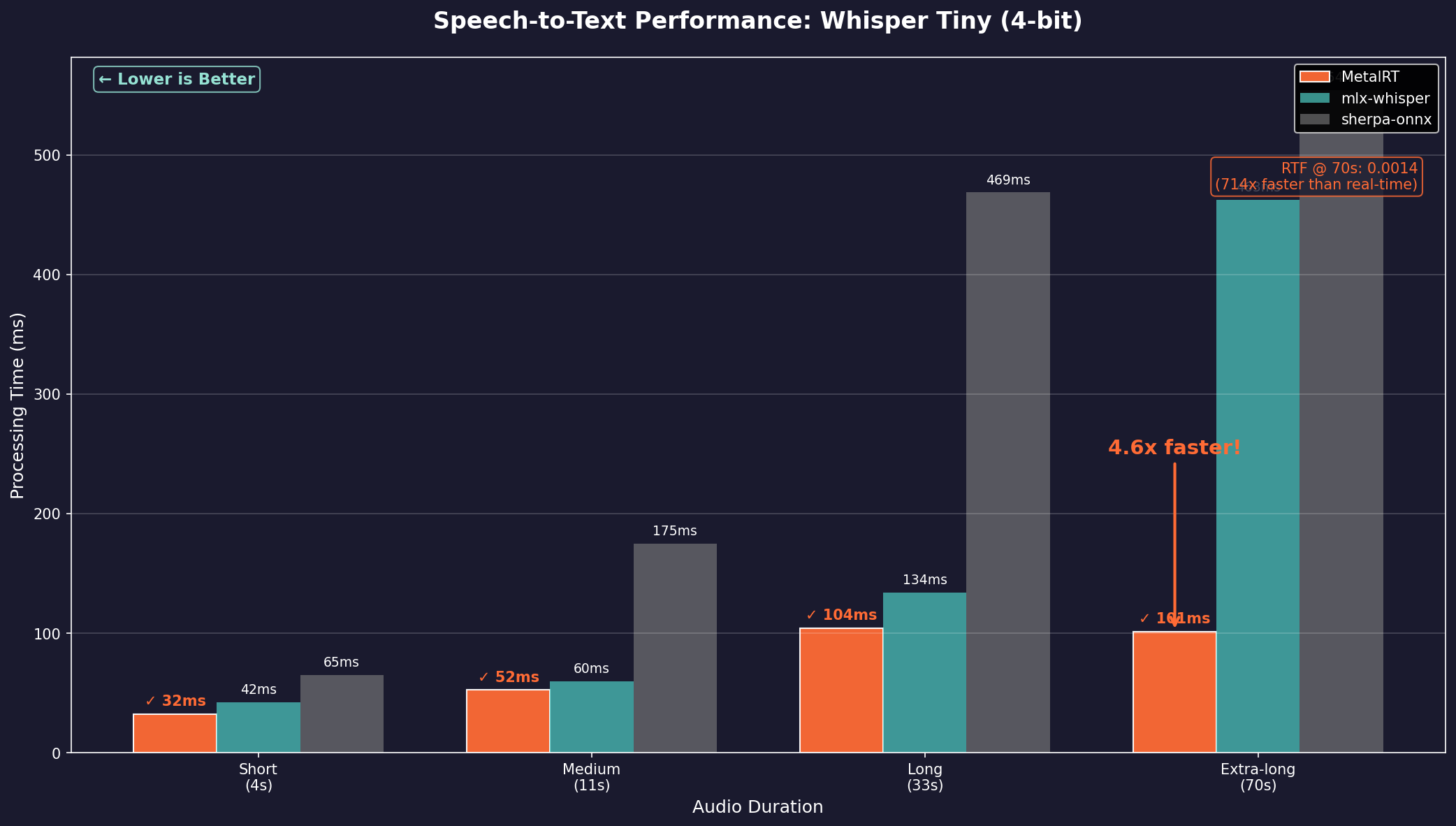
MetalRT becomes the first inference engine to handle LLMs, Speech-to-Text, and Text-to-Speech on Apple Silicon. 101ms to transcribe 70 seconds of audio. 178ms to synthesize speech. 4.6x faster than Apple MLX.
 MetalRT
MetalRTMarch 3, 2026
MetalRT delivers 658 tok/s decode and 6.6ms time-to-first-token, winning decode on 3 of 4 models we tested on a single M4 Max.
RunAnywhere Labs
A research-first inference lab. We hand-write the kernels that make consumer silicon fast — and open-source the SDKs and infrastructure that run them on every platform.
Open Source
Research